A Step-by-Step Cloud Incident Response Guide for Security Teams

Cloud security breaches can occur almost any time. Once threat actors gain access to the cloud infrastructure, they can rapidly move to other regions and services, leveraging the automation and scalability of cloud systems within minutes. The average cost of a cloud data breach is $4.4 million, and the estimated time to detect and contain an incident is 277 days. Many security teams still rely on incident response procedures for on-premises environments.
This document provides step-by-step guidance to cloud incident response using NIST frameworks. The examples have been tailored to AWS, Azure, Google Cloud, and multi-cloud environments.
Why Cloud Incident Response is Different
Traditional incident response frameworks rely upon the assumption that systems are static and have defined boundaries. Cloud environments operate differently as resources can be created and terminated on demand. Containers may run only for seconds, while serverless functions run in milliseconds, too often providing limited evidence for forensic activities.
Cloud incidents can unfold very quickly. A typical attack can start with compromised credentials, followed by enumeration of resources, discovering misconfigured storage to exfiltrate data, setting up persistence with new IAM users, and moving to another cloud environment within the hour.
Primary Cloud Attack Vectors
| Attack Vector | Description | Consequences |
| Identity-Centric Attacks | Overly liberal IAM roles, compromised credentials, privilege escalation via misconfigured server | Attackers have valid paths to access, with each provided less scrutiny from protective mechanisms. |
| Configuration Drift | Exposed APIs, open storage buckets, overly liberal firewall rules, and no logging | The leading cause of cloud data breaches is simple mistakes with drastic consequences. |
| Ephemeral Resource Exploitation | Container compromise, serverless function abuse, auto-instrumenting forever, too many function calls | Contributes to challenges in traditional forensics; evidence rapidly dissipates. |
Embracing a Modern Framework
Effective cloud incident response means shifting from reactive cleanup to a proactive, ongoing workflow focused on the cloud. The NIST (SP 800-61) Incident Response framework is proven, but cloud environments need specific adjustments.
| The original NIST framework | Cloud-adapted framework |
| PreparationDetection & AnalysisContainment, Eradication & RecoveryPost-Incident Activity | Preparation & Readiness (Govern, Identify, Protect)Incident Response (Detect, Respond, Recover)Post-Incident Activity (Lessons Learned and Risk Reduction |
This adaptation emphasizes automation, which is essential for responding to incidents at cloud speed.
Phase 1: Preparation and Readiness
Teams that are effective in managing security incidents in the cloud are proactive in their work and are prepared to respond as incidents arise.
- Develop Cloud Incident Response Plans: General incident response programs do not translate well in the cloud. Plans and playbooks should include provider-specific steps, multi-cloud considerations, the shared responsibility model, and flexible action plans for a more fluid environment.
- Build Forensic Readiness: Determine data retention requirements based on compliance requirements while being mindful of storage costs. Seek features that provide log immutability, such as AWS CloudTrail Integrity Validation or Azure Monitor log integrity, that would protect evidence. Prepare tools such as automated snapshots or evidence scripts to allow for rapid action by incident responders.
- Conduct Readiness Exercises: Conduct tabletop exercises at least quarterly to expose gaps in decision-making and escalation. Conduct red team exercises to test detection and response time. Review and validate playbooks each year at a minimum to keep up with cloud service changes.
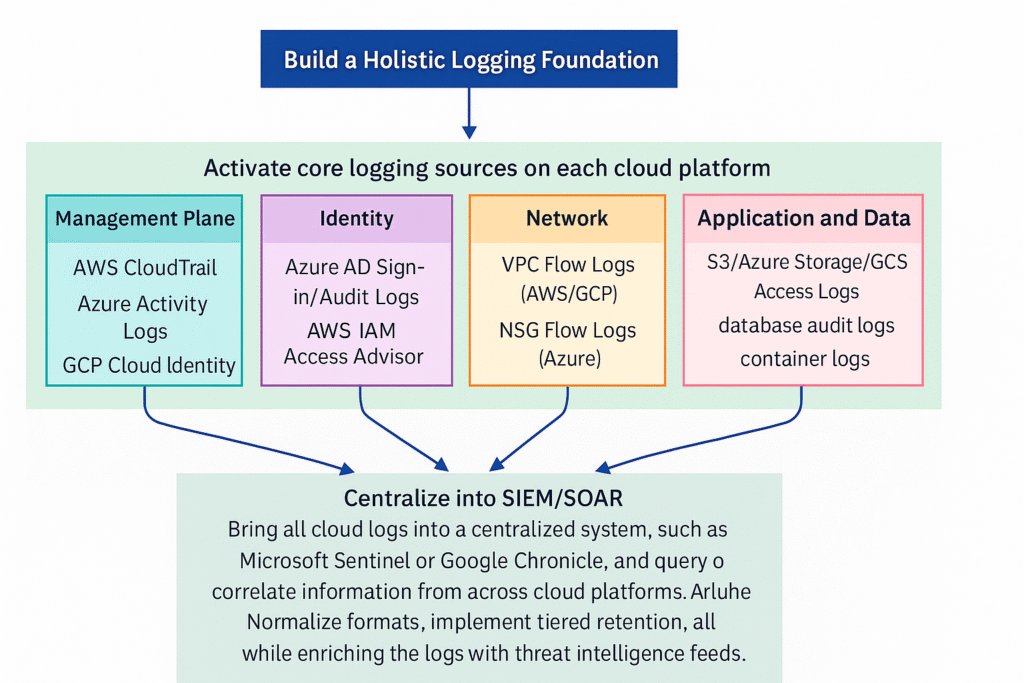
Phase 2: Incident Response (Detect, Respond, Recover)
Detection and Analysis
Confirm the Incident: Determine whether the raw alerts from AWS GuardDuty, Azure Defender, or GCP Security Command Center are real threats or false positives. Breaking down security events (a single failed login) versus a security incident (credential stuffing campaign).
Correlate and Prioritize
- Combine signals from cloud-native tools, CSPM platforms, identity providers, and network monitoring.
- Filter benign events (i.e., authorized scans, routine sysadmin tasks, automated tooling).
- Identify toxic risk combinations (an exploitable attack path).
- Using the MITRE ATT&CK for Cloud framework, map activity to begin to anticipate the attacker’s next move.
Identify Scope: Determine which cloud resources, identities, data (PII or proprietary), and networks are compromised. Also, establish root causes such as compromised credentials, exploited vulnerability, misconfiguration, or supply-chain compromise.
Detecting Modern Attacks with Security Graph
The complexity of modern cloud infrastructure, such as Kubernetes clusters, serverless functions, and distributed identities, creates attack paths that traditional hardening techniques and security scanner detections will never reveal. Security Graph models essentially address this issue by representing all of the cloud infrastructure as an interconnected graph that represents relationships between resources, identities, permissions, and network connections.
When security events occur, the graph immediately indicates blast radius, attack paths, and which sensitive data is impacted—all necessary visibility that would normally take hours of manual correlation to discern, takes seconds. Leading Security Graph platforms like Wiz are pioneering this unique architecture and nearly unlimited capability of rapidly assessing the context of incidents through the speed of cloud attacks.
Recovery and Verify
- Restore from known clean backups that are verified to predate the compromise
- Verify integrity before returning to production
- Deploy monitoring on recovered resources
- Perform validation scans for next-generation vulnerabilities and malware
- Inform stakeholders: executives, customers, regulators, cloud providers
Phase 3: Post-Incident Activity (Lessons Learned and Risk Mitigation)
The active part of the incident response phase has ended. You have completed the work. Now is the time to learn as an organization. In this phase, you will build better security controls and better incident response processes based on experiences with incidents.
Conduct Lessons Learned Review
Plan a post-mortem meeting within two weeks after the incident has been closed:
- Invite all stakeholders: Work with the incident response team, security operations staff, IT operations staff, affected business units, legal counsel, and executive sponsors.
- Walk through the incident timeline: Go through the different phases of the incident (detection, containment, eradication, and recovery) in chronological order. This will show you what worked well and what did not.
- Document gaps: Record weaknesses in security controls that allowed the initial attack, weaknesses in the detection capability that delayed discovering the incident, and weaknesses in the process that prevented an effective response.
- Avoid blaming: Focus on the problem rather than an individual’s performance. Both blameless and the focus on improvement will lead to an honest review without concern for future reporting of incidents.
- Document action points: Turn lessons learned into action points that list action items, owners, and deadlines. Recommendations such as “improve security” are not actionable, but something precise like “Implement MFA on all administrative accounts by Q2″ is an action point, which will be more effective in realizing change.
Update and Adjust Playbooks
You can never complete your incident response planning. Update incident response templates to incorporate lessons learned from this incident. Add new response procedures for attacker techniques employed during this incident. Add detection logic to identify attacker techniques that evaded your security monitoring functions. Tune detection rules that produced excessive false positive notifications during the incident response.
Rank security investments based on the root cause that emerged from your investigation. If the lateral movement was the result of weak IAM permissions, it is time to formulate an identity security improvement plan. If you experienced technical difficulties when collecting evidence, refine the evidence collection procedure. Test refined procedures before your next incident.
Define and Monitor Metrics
Quantify the effectiveness of your incident response process to drive continual improvement:
- Mean Time to Recover (MTTR): Monitor the time from when you first detected the incident until you contained the incident. As your incident response process and tools improve, aim to reduce time to recover.
- Dwell Time: If an attacker operated undetected in your environments, such as the cloud, then keep track of how long they operated. You should ideally be able to detect exposure threats that could greatly reduce dwell time.
- Post-Incident Hardening Rate: This is a percentage that indicates how many action points identified ways to improve the security posture, were implemented within 90 days of incident closure. This indicates the commitment of your organization to learn from incidents.
- Incident Recurrence Rate: After implementing security improvements, did a similar incident recur? If so, you’ve either remediated it inadequately or your precautions did not work effectively against new attempts.
Next Steps to Increase Readiness
Conduct an audit of compliance against multiple frameworks (e.g., NIST SP 800-61, ISO 27001, and SOC 2) to assess potential gaps between documented procedures and what can actually be accomplished.
Invest in an automated CSPM (Cloud security posture management) platform to perform cloud threat detection, evidence collection, and initial containment. This practice is more well-informed than any manual incident response practice. Additionally, AWS Step Functions, Azure Logic Apps, or Google Cloud Workflows can automate codifications, resulting in faster application of procedures and consistency.
Remain aware of threats by consuming threat intelligence feeds/reports, responding to all security advisories and recommendations posted by cloud service providers, participating in financial services and overall security communities, and through continuous training on evolving cloud services and techniques that attackers use to exploit the cloud and achieve their objectives successfully.
The question is not whether your cloud environment will have a security incident, but whether your incident response team can detect, contain, and recover from the incident when it occurs. Preparation is the difference between a minor security event and a catastrophic security breach.
Conclusion
Cloud incident response in 2025 requires readiness, automation, and constant adaptation. Organizations that view incident response as a workflow that continually operates on events they respond to for the sake of responding are preparing to detect incidents at speed, respond with appropriate actions, and minimize business effects.
The fundamentals still matter: Misconfigurations are still the cause of most cloud data breaches. Identity threats capitalize on over-permissive Identity and Access Management (IAM) and compromised credentials. Unpatched vulnerabilities can provide entry points for the attacker. Security teams that continuously monitor cloud security posture and proactively strengthen controls will minimize incidents. Preventing incidents is exponentially more valuable than managing and responding to preventable ones.
- Cyber Security